Thinking Outside the BBox: Unconstrained Generative Object Compositing
- ECCV 2024 -

Abstract
Compositing an object into an image involves multiple non-trivial sub-tasks such as object placement and scaling, color/lighting harmonization, viewpoint/geometry adjustment, and shadow/reflection generation. Recent generative image compositing methods leverage diffusion models to handle multiple sub-tasks at once. However, existing models face limitations due to their reliance on masking the original object during training, which constrains their generation to the input mask. Furthermore, obtaining an accurate input mask specifying the location and scale of the object in a new image can be highly challenging. To overcome such limitations, we define a novel problem of unconstrained generative object compositing, i.e., the generation is not bounded by the mask, and train a diffusion-based model on a synthesized paired dataset. Our first-of-its-kind model is able to generate object effects such as shadows and reflections that go beyond the mask, enhancing image realism. Additionally, if an empty mask is provided, our model automatically places the object in diverse natural locations and scales, accelerating the compositing workflow. Our model outperforms existing object placement and compositing models in various quality metrics and user studies.
Model Architecture
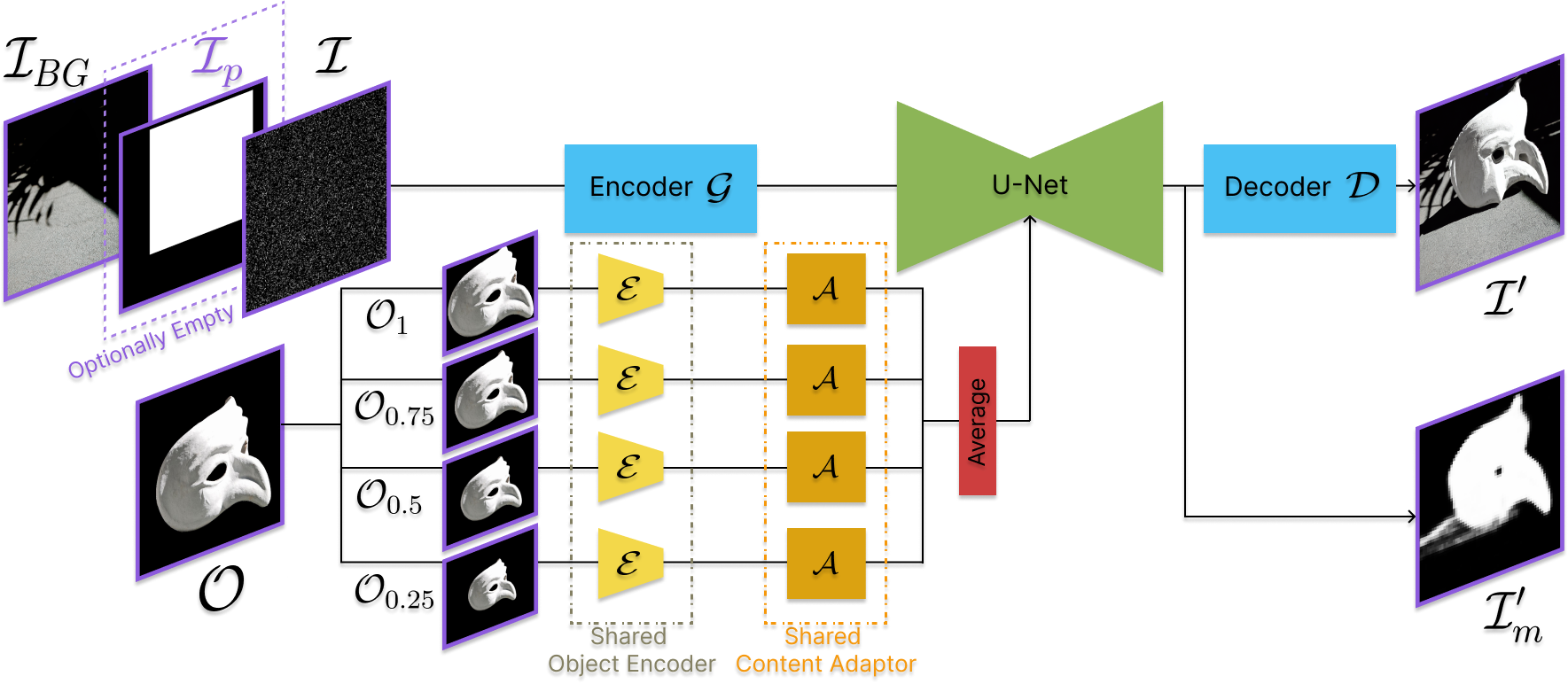
The background image and a mask are concatenated with the 3-channel noise and fed into our model's backbone, Stable Diffusion 1.5 (SD), consisting of a variational autoencoder (G, D) and a U-Net. The U-Net in our SD framework estimates an additional binary mask that indicates generated object pixels.
The foreground object (O) is processed by an object encoder (E), based on CLIP ViT-L/14, and a content adaptor (A) aligning embeddings to text embeddings. We observe that E is scale-dependent: Larger object encoders emphasize finer details, while smaller object encoders prioritize high-level structure. Thus, we incorporate multiscale encoding.
Diverse Natural Composite Images

The position mask is optionally empty. By feeding an empty mask (all values set to -1) instead of a position mask, our model can place objects in diverse natural locations and scales. This eliminates the laborious task of manual mask creation, accelerating the user workflow for image compositing. Moreover, the generated outputs can serve as location/scale suggestions to assist in creative ideation.
Comparison to Generative Object Compositing Models

When providing a position mask, our model outperforms SoTA generative composition models. Due to its unconstrained compositing approach, it is able to outperform mask-based state of the art image compositing models: (i) allowing the network to leverage information from the entire background image rather than just a masked area leads to better background preservation (rows 3 to 6); (ii) enabling object effects such as shadows and reflections beyond the bounding box allows for more natural and realistic composite images (rows 3-4); (iii) our model's success is not bounded by the accuracy of the bounding box thanks to its ability to adjust any misaligned bounding box (rows 1-2).
Comparison to Object Placement Prediction Models

We also compare our model to state-of-the-art object placement prediction models: TopNet, GracoNet, PlaceNet and TERSE, for evaluating object placement accuracy. We find that, without being explicitly trained for placement prediction, our model performs comparatively to the best SoTA models.
Applications

The unconstrained generation feature of our model allows for users to easily provide a rough desired location. Even if this mask is not accurate, our model can naturally align the object and automatically add any necessary shadows (Example a) and reflections (Example b) that extend beyond the mask, resulting in a realistic composite image. It also enables easy addition of interacting objects in a scene without altering the surrounding background or existing objects (Example c). Additionally, our model is able to sequentially place different objects into a scene (Example d), ensuring that their relative location, scale and lighting are semantically and visually coherent.